12.1 Introduction to Cloud-Native Applications
Learning Objectives
By the end of this section, you will be able to:
- Analyze the differences between monolithic and microservices architectures
- Understand the architecture of cloud-native applications
- Learn the features of cloud-native applications
- Relate to the benefits of cloud-native applications
- Understand best practices and tools used to develop cloud-native applications
- Apply the tools used in cloud-native application development
- Envision the road ahead for cloud-native applications
Cloud computing makes it possible for organizations to offer solutions in the cloud and use cloud services to streamline development and deployment. As organizations look to the cloud to solve today’s business problems, they may opt to create, deploy, and manage cloud-based or cloud-native applications. As noted earlier, cloud-native development relies on four key principles that help with designing applications for the cloud, as illustrated in Figure 12.2.
In a nutshell, a cloud-native application uses a microservices architecture that takes full advantage of the benefits of the cloud such as scalability and on-demand services. Cloud-based applications are adaptations of legacy applications, or monoliths, migrated to a cloud provider. They are designed to leverage cloud platforms to facilitate the interoperation of local and cloud components. Although cloud-based applications do leverage cloud platforms to some degree, they are generally deployed as a single monolithic component, which makes them inflexible as full-stack upgrades are likely necessary and require downtime.
Different from cloud-based applications, cloud-native applications leverage microservices architectures that structure applications as coordinated collections of small, independent services that are self-contained and are deployed in software containers managed by a container orchestrator.
Both cloud-based and cloud-native applications can run on public, private, or hybrid cloud infrastructures. A hybrid cloud combines private, public clouds, and bare metal or virtual environments. What distinguishes cloud-native applications from cloud-based applications is the fact that they take full advantage of inherent characteristics of the cloud, such as resource pooling, on-demand self-managed services, automation, scalability, and rapid elasticity, to name a few.
Monolithic vs. Microservices Architecture
A monolithic architecture consists of software units that are united through a single codebase. In a monolithic architecture, all the different components of the application, including the user interface, business logic, and data access layer are tightly integrated and deployed as a single software unit. Mainframe applications or legacy e-commerce websites were based on monolithic architectures.
A microservice is a self-contained software unit that typically implements a single business capability. Because microservices are independent and loosely coupled, changes to an individual microservice can be deployed separately and do not require updating the entire application. This in turn streamlines the application development and minimizes downtime.
Monolithic architectures typically consist of a user interface, business logic, and data access layers that are tightly coupled and generally dependent on one another to operate properly. An application that conforms to a monolithic architecture (also called a monolith) implements all the business capabilities together, and data is shared across all these capabilities. Monoliths are typically easier to develop and deploy, but they may become difficult to manage and scale over time. The basic difference between a traditional monolithic architecture and a microservices architecture is illustrated in Figure 12.3.
As an example of a monolith, consider an application that provides a catalog of products that can be ordered online. An application designed using a monolith architecture is shown in Figure 12.4. The application includes a user interface. The business logic layer includes various components such as an inventory system for the product catalog, a basket service to order products, a payment system to purchase the products, and a reporting system that generates reports on sales and customer interests. A component is a software unit that encapsulates a set of related functions and data through a well-defined interface and specified dependencies. A single database is typically used as part of the data access layer for the entire application.
These are highly dependent software components that use shared libraries. Any changes to one component require understanding what other components need from these shared libraries. Such changes can cause dependencies between components to break over time. The various components are also programming language and framework dependent. New components need to be implemented in the same programming language or use the same framework as the existing components.
Other challenges with monoliths are managing growth and ensuring scalability. Over time, as new functionality is added to meet the needs of end users, the monolith grows and becomes more difficult to manage. Deploying the monolith then becomes challenging as it requires more effort to stabilize it and get it to run smoothly. Scaling a monolith also becomes more difficult over time. For example, during a holiday season with a rapid increase in sales, the payment system component may require additional capabilities to support a sudden increase in transactions. To add the necessary capabilities to just the payment system component, the entire monolith application needs to be duplicated. The problem with this is that deploying a second instance of the entire application and making it available to end users may take a lot of time. Before this gets done, the holiday season may have ended already and the version of the application that was available was only able to support a limited number of transactions. The second instance of the application is useless at this point despite the effort it took to deploy it. A scaled version of the monolith application is shown in Figure 12.5.
In contrast, microservices architectures consist of small loosely coupled services that run independently and connect via a network. Applications that conform to a microservices architecture include a collection of modular components that run independently and provide a well-defined API to facilitate communication with other services. Instead of using a shared database across all business capabilities, each microservice that implements a single business capability contains its own datastore, the type of which depends on the type of data needed.
If the sample monolith application discussed earlier is implemented using a microservices architecture, each one of its components (i.e., the inventory system, basket service, payment system, and reporting system) becomes an individual microservice. These microservices each run in separate containers and communicate via APIs. An application designed using a microservices architecture is shown in Figure 12.6.
Components in a microservices architecture are independent of each other. Individual microservices can be changed without affecting the other microservices. If a microservice fails, the rest of the application is not affected.
Microservices are also programming language and framework independent. New microservices can use different programming languages or frameworks. For example, a team responsible for the inventory system can use a programming language or framework that is different from the ones used to implement the payment system. It is also easier to grow or scale a microservices-based architecture.
Additional functionality can be added to individual microservices independently from the other microservices. This allows teams to iterate faster to bring value to end users. Microservices can also scale independently, as shown in Figure 12.7. During a holiday season with a rapid increase in sales, additional capabilities can be added to the payment system microservice quickly without affecting the other microservices. These additional capabilities can be scaled down as needed when sales decline after the holiday season ends.
In summary, a monolith bundles all the capabilities together in a highly dependent way and requires them to use the same programming language and framework. Monoliths are more difficult to grow and scale because they require that the entire application be deployed as a second instance. In contrast, a microservices-centric application places individual capabilities in separate microservices that are deployed via containers and communicate via APIs. Individual capabilities are programming language and framework independent. They are easier to grow and scale independently.
Link to Learning
The article Microservices discusses the characteristics of a microservices architecture in contrast to a monolith architecture.
Components vs. Services
Building applications using components is a desirable approach. In the case of monoliths, this is typically achieved by using libraries as components and compiling or linking them into a single program or process that accesses them using “in-process” function calls. In contrast, “services” in a microservices-centric application are “out-of-process” components that communicate with each other using a web service request, or a remote procedure call. Figure 12.8 illustrates how components are accessed in a monolithic architecture as compared to a microservices architecture.
As noted earlier, services used by microservices-centric applications are independently deployable so that changes to any service do not affect other services. This assumes services are well encapsulated and designed with minimally cohesive service boundaries. The use of web services calls and RPC makes this easier to achieve. A web service is a unit of software that is available as a resource over the Internet. A remote procedure call (RPC) is a request-response protocol used by a program to access services from other programs over a network. However, there are downsides to this approach. RPCs are more expensive than in-process calls, and thus remote APIs need to be coarser-grained (i.e., coarse-grained APIs expose more methods in their interfaces as opposed to fine-grained APIs).
One challenge to using services is changing the allocation of responsibilities between components. This can be challenging especially if the service consists of multiple processes deployed together such as an application process and a datastore process that are only used by that service. Another challenge is that it may be difficult to get the components’ service boundaries right. In other words, the difficulty is to fit software into a component that can be used as a service. Services use APIs, thus any changes to the API must be coordinated with other components. API changes must be backward compatible so components that do not use the latest updated version of the API can still function. Finally, testing is also more complicated.
SOA vs. Microservices
The microservices architecture is not the first architectural style to make use of self-contained components and implement individual business capabilities. The service-oriented architectural style, a well-established style of software design, commands the same approach. A service-oriented architecture (SOA) requires that conforming applications be structured as discrete, reusable, and interoperable services that communicate through an enterprise service bus (ESB) via message protocols such as SOAP,1 ActiveMQ,2 or Apache Thrift.3
An enterprise service bus (ESB) implements a bus-like communication system between interacting service providers and service consumers. The services, ESB, and messaging protocols collectively make up an SOA application. In Figure 12.9, the architecture shown on the left illustrates a typical SOA compared to the typical microservices architecture illustrated on the right. As is the case for services in a microservices architecture, SOA services can be updated independently. However, the ESB represents a single point of failure for the entire system.
Different from services in an SOA, microservices usually communicate with each other statelessly using lightweight REST protocols implemented via HTTP. Furthermore, microservices can be implemented using different programming languages and frameworks because they can communicate through programming language-agnostic APIs. Advancements in containerization technologies make it possible to deploy, upgrade, scale, and restart microservices independently, better controlling their life cycles. In case a microservice fails, the rest of the application is unaffected. Thus, applications using microservices can be more fault tolerant because they do not rely on a single ESB as is the case for SOA applications.
Concepts In Practice
Microservices Architecture and Cloud-Native Applications
As discussed in Chapter 9 Software Engineering and Chapter 10 Enterprise and Solution Architectures Management, architectural styles, architectural patterns, and design patterns are typically used to enforce the quality attributes of software solutions. The microservices architectural style is used to break monolithic applications into smaller services based on business capabilities. It is partially based on the SOA style but does not rely on an enterprise service bus to enable communication between services.
One example of a microservices design pattern is the Backend for Frontend (BFF) Microservice Design Pattern.4 This design pattern involves creating dedicated back-end services tailored to the specific needs of front-end clients. The goal of this pattern is to ensure an efficient and streamlined interaction between the front-end and back-end components. As an example of how to use this pattern, consider an e-commerce platform like the online products catalog sample described above. The e-commerce platform may serve both web and mobile client applications. Implementing the BFF pattern means creating dedicated back-end components that serve each client application. Because the user interactions between these two client applications are different, the APIs between these clients and the dedicated back-end services can be optimized to best suit those client types.
In addition to optimizing the API gateway, the microservices architecture utilized also efficiently allocates resources to each service that a cloud-native application uses, making the application flexible and adaptable to a cloud architecture. Containers are an architectural pattern that is used to deploy microservices on any platform that operates a container engine runtime. Combining microservices and containers with another architectural pattern referred to as container orchestration makes it possible to scale, manage, and automate the deployment of containerized applications based on microservices. This is an example of how a combination of architectural styles and related patterns can drastically improve the quality of enterprise applications. However, as noted earlier, there are challenges associated with the use of microservices and other architectural styles that also must be considered when designing an enterprise solution.
Microservices Challenges
Microservices enhance a development team’s ability to leverage distributed development. Development time can be reduced as microservices can be developed concurrently. However, there are known challenges to shifting to a microservices architecture. In addition to complexity and efficiency being two major challenges of a microservices-based architecture, the following eight challenge categories have been identified.
Building Microservices
Some microservices may need to access other microservices to provide certain application functionality. This causes dependencies between microservices. Time must be spent identifying these dependencies. Added dependencies between microservices can result in completing one build that triggers several subsequent builds.
Another type of dependency is data sharing where one microservice may need access to data managed by another microservice. Some concerns with data sharing include scaling. As microservices are added, to provide data consistency and redundancy, a microservice that requires a schema change in a database must be shared with other microservices. These concerns should also be taken into consideration when addressing dependencies.
Microservices Connectivity
Microservices-based applications consist of several microservices that need to communicate with each other. Microservices run in containerized environments where the number of microservices instances and locations change dynamically. Service discovery can be used to locate each microservice instance. Without service discovery, a microservices-based application can be difficult to maintain.
Versioning of Microservices
A microservice might be updated to satisfy new requirements or address some design issues. Other microservices that depend on an older version of the updated microservice could fail. Dependencies between microservices when updating a microservice can lead to breaking backward compatibility. One way to address this is to build in conditional logic that either appends the version number or tracks versioning, which can become difficult to manage. Alternatively, multiple live versions can be provided for different clients, but they can also become difficult to manage.
Testing Microservices
Testing microservices can become more challenging, particularly with integration testing and end-to-end testing. A single transaction carried out in an application can span across multiple microservices. A failure in one microservice can lead to failures in other microservices. In addition, failures can occur in the microservice itself, in its container, or in the network interconnecting the microservices, making it more challenging to design integration tests. For these reasons, an integration test plan should factor in interdependencies between microservices.
Link to Learning
Various tools and/or frameworks can help automate testing in a microservices testing such as Selenium automation testing.
Logging Microservices
Microservices are distributed systems and therefore traditional logging is ineffective when determining which microservices failed. As more microservices are added, the complexity of logging microservices activities grows exponentially and becomes more difficult to manage. In particular, logging aggregation is needed to track errors that might span across several microservices, as shown in Figure 12.10.
Debugging Microservices
Remote debugging through a local integrated development environment will not work across several microservices. An IDE provides developers access to resources (e.g., source code editor, build automation tools, debuggers) to design, develop, debug, and test programs. Debugging a microservices-based application is challenging because errors are not propagated in a useful manner. In addition, logging formats can also differ across microservices. Debugging requires tracing through various error messages and status codes across the network, which is inefficient and makes it difficult to acquire the required information to debug the errors. Currently, there is no easy solution to debugging such applications effectively; however, tools (e.g., Helios,5 Rookout,6 Lightrun,7) do exist today to address this problem.
Deployment of Microservices
A monolithic application’s deployment may seem less complex because it is limited to a single deployment unit. In contrast, a microservices-based application is more complex to deploy because the interconnections between the microservices are more visible. In addition, there are more deployable units and the dependencies between them require more complex configurations. This increase in the number of deployable units imposes an order in which microservices need to be deployed. It also requires more investment in automation to practically manage them and help ensure that the whole microservices-based application is resilient and limits the risks of failovers.
Monitoring Microservices
Because of the interdependencies between microservices, any downtime of a microservice resulting from updates or failures can cause cascading failures to other microservices. Monitoring a microservices-based application is challenging because it requires knowledge of the performance and availability of API calls for all the microservices in the application. In addition to monitoring the containers hosting the microservices, it is crucial to have a centralized view of the entire microservices-based application. This holistic view helps pinpoint any potential issues and ensures effective problem identification.
Cloud-Native Application Architecture
A cloud-native application takes advantage of cloud computing frameworks to implement a collection of loosely coupled microservices in the cloud. The cloud-native application architecture makes it possible to efficiently allocate resources to individual microservices that the cloud-native application uses. An example of a cloud-native application architecture is illustrated in Figure 12.11.
The cloud infrastructure, shown in Figure 12.11, is provided by a cloud computing platform. The cloud computing platform also provides a scheduling and orchestration service to manage the containers that the cloud-native application microservices are deployed in. Microservices used in a cloud-native application typically run in different locations within a cloud platform, which enables the application to scale out horizontally. Therefore, cloud-native applications must be designed with redundancy in mind. This allows the application to withstand equipment failures.
Finally, the cloud-native application and runtime environment is where the cloud-native application operates. A cloud-native architecture leverages a commoditized microservices architecture. In this architecture, business capabilities are implemented as cloud-managed microservices, which makes the cloud-native application more reliable and scalable.
Cloud-native applications should be designed to include standardized logging and support events that can be associated with a standard logging catalog. Scaling and managing multiple microservices require core services such as load balancing, service discovery, and routing, which are all managed by the scheduling and orchestration layer. In summary, designing cloud-native applications to leverage the services of a cloud computing framework makes it possible to add and support new business capabilities more quickly.
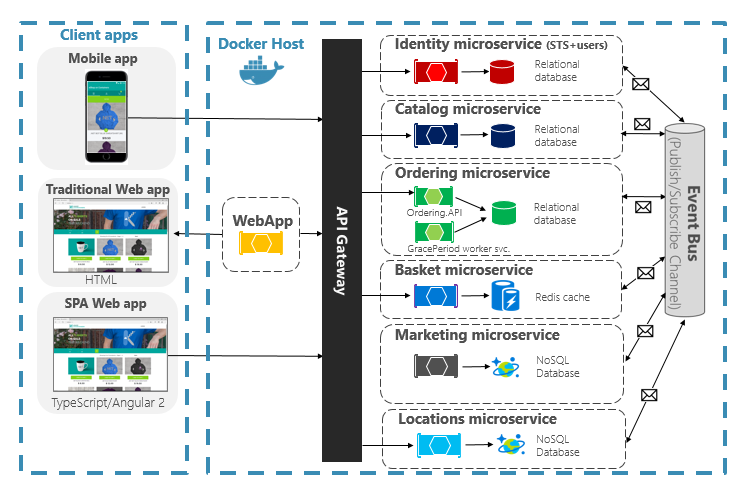
Sample Web-Native Architecture
Figure 12.12 illustrates a sample web-based, cloud-native “web-native” architecture. This cloud-native application consists of several microservices that are deployed and managed on the cloud. Each microservice is self-contained as well as programming language and framework independent. Microservices are containerized and managed by a container orchestrator. Each microservice contains its datastore that best suits its data needs. Some of these datastores are relational databases whereas others are NoSQL databases.
One of the microservices stores its state in a distributed Redis cache. An API gateway is used to route traffic between client apps and microservices. Most important, this cloud-native application takes full advantage of the scalability and resiliency features of modern cloud platforms.
Industry Spotlight
Cloud-Native Application in Industry
Cloud-native applications are broadly used in the industry today. In particular, Netflix, Uber, and WeChat expose cloud-native systems that consist of many independent services. Can you elaborate on the specific characteristics of these systems and explain why cloud-native is more suitable for the types of solutions provided by these companies? As an example, Netflix published the article “Completing the Netflix Cloud Migration”9 discussing the benefits of this migration. A case study10 was also published discussing Netflix’s adoption of cloud-native computing environments for their services.
Features of Cloud-Native Applications
As mentioned previously, cloud-native applications, in contrast to cloud-based applications, leverage inherent characteristics of the cloud such as resource pooling, on-demand self-services, automation, scalability, and rapid elasticity. Below is a list of the key capabilities of cloud-native applications that make this possible.
Microservices-Based Applications
As noted earlier, microservices are based on a software architectural pattern where every functionality of a corresponding monolithic application is placed into its own microservice because it implements a separate business capability. These microservices are deployed and run in containers that communicate over application APIs, event streaming, and message brokers. Scheduling and orchestration tools manage these containers as they help coordinate and schedule the containers used to implement application services running on computing resources. Microservices development teams can rapidly add new capabilities whenever a business needs change.
Microservices can also be scaled, when a single capability faces too much load, independently of other microservices. This reduces the time and cost associated with having to scale another instance of the entire application. Typically, scaling is achieved by containerizing microservices and managing the containers using a container management framework (e.g., K8s) provided by a cloud platform. Another alternative is to leverage Function as a Service (e.g., AWS Lambdas or Google/Microsoft functions) as part of microservices and rely on cloud platform(s) to manage scalability.
Microservices are also distributed and loosely coupled, making them easier to iterate through. Because microservices are independent and just communicate over APIs, teams can commit code for microservices through a DevOps pipeline. Once tested, the microservices can be automatically deployed, making it easier for teams to iterate as fast as they need to bring value to end users. Additionally, these iterations are minimal, and if there is any instance where a microservice fails, the rest of the application is still functional, making updates less risky.
Best-Suited Languages and Frameworks for Microservices
The programming language and framework are chosen based on what is best suited for the functionality the microservice provides. Cloud-native applications are polyglots, meaning microservices are language and framework independent, making it possible to choose different technology stacks and frameworks for different microservices of a single cloud-native application.
Container-Based Framework
A container is a standardized unit of software that logically isolates an application, enabling it to run independently of physical resources. The packaging of a standardized unit of software that isolates an application, enabling it to run independently of physical resources is containerization. Containers provide consistent, complete, and portable environments for running applications anywhere, including all the system files and dependencies needed to run applications. Containerization facilitates the creation of cloud-native applications and maximizes the benefits of containers. Containers keep microservices from interfering with one another. They keep applications from consuming all the host’s shared resources. They also enable multiple instances of the same microservice.
Containers boost DevOps efficiency and effectiveness through streamlined builds, testing, and deployments. They also provide consistent production environments that are isolated from other applications and processes. Because containers can run consistently anywhere, they facilitate hybrid and multicloud computing environments. Containers are lightweight because they are isolated from the operating system layer of a computer system. This makes them efficient and light on resources. Containers are portable because containers include all required dependencies and configurations, thus they, and the code contained within them, can be moved between different environments.
Figure 12.13 shows how containers in production can run on any computing resource that has a containerization platform. Containers are scalable due to their small size, making it easy to rapidly start up, scale, or shut down containers depending on use. Containers can be cost effective because they require fewer resources and are easier to scale.
Containers are instances of a container image. A container image represents a binary state that is built by “layering” an application and its dependencies on top of the required “layer” of binaries and libraries of the operating system, which establishes a parent-child relationship between image layers. Figure 12.14 shows the process for building an image. For example, at the root of the parent-child tree is a layer that provides a formatted file system. On top of this layer is a base image that might contain Ubuntu, Debian, CentOS, or some other operating system. This base image can then be a parent of some other image, such as an image that adds Python. Finally, another image on top of the Python image may contain the application that was implemented in Python, such as a Django web application. Django is an open-source web application framework, which is a software framework that facilitates the development, maintenance, and scaling of web applications. In effect, these layers of images are arranged in an image hierarchy where each layer creates a snapshot.
An advantage of this hierarchical structure is that it makes it possible to share images at different levels of the hierarchy. If you want to run the Django web application, you pull the entire hierarchy of the built image. However, other layers of the hierarchy can be shared with other things (e.g., the Python layer), reducing the need to shift entire application stacks. The built container image is an independent and self-contained artifact that can be deployed in any environment that has a container runtime environment (e.g., Docker) installed. The Open Container Initiative is a community trying to govern and address uniformity and standardization of the container runtimes and images. This is an important initiative for containers to be able to “build once and run anywhere.”
API-Based Framework
Microservices that rely on each other communicate using well-defined APIs. These APIs help configure the infrastructure layers to facilitate resource sharing across them. APIs connect microservices and containers while providing simplified maintenance and security. They enable microservices to communicate between otherwise loosely coupled services without sharing the same technology stacks, libraries, or frameworks. Cloud-native microservices use lightweight APIs that are based on protocols such as representational state transfer to expose their functionality. The architectural style for providing standards between resources so they can communicate with each other over the Web is called representational state transfer (REST).
Dynamically Orchestrated Framework
As already mentioned, the scheduling and orchestration layer of a cloud computing framework manages the containers microservices are deployed in. As applications grow to span multiple containers deployed across multiple servers, operating them becomes more complicated. Container orchestration tools (e.g., Kubernetes) can help coordinate and schedule many containers. They can also help scale container instances to provide more computational power. For example, the orchestration tool, depicted as “Master” in Figure 12.15, deploys the microservices in containers (single instances, initially) of an application on a computing resource.
As the microservices’ consumption of the computing resources increases, additional resources are added, and the orchestration tool will start scheduling and scaling the microservices. An orchestration platform helps schedule the microservices and containers and optimizes the use of the computing resource. In contrast, a monolith application is not designed to leverage an orchestration platform and requires the use of load balancers. Other services, such as service discovery, also need to be performed manually. For example, if microservices need to communicate with one another, they cannot find the IP addresses of their respective containers and check if they are running. This is handled automatically by the orchestration platform (i.e., Microsoft AKS, Amazon AWS EKS, Google GKE). An orchestration platform typically runs workloads by placing corresponding containers into pods that run on nodes (i.e., a virtual or physical machine). Multiple nodes are typically grouped into clusters to ensure scalability. Pods are the smallest deployable units of computing; they group multiple containers, provide shared storage and network resources, and specify how to run the containers. The orchestration platform provides support when a pod that contains a running microservice container goes down. In that case, another pod is brought up rapidly and brings it within the purview of that service automatically. Figure 12.16 shows how microservice containers are scaled and managed in the case of failure.
Agile DevOps and Automation using CI/CD
DevOps is a methodology that combines Agile software development and IT operations to deliver software faster and of higher quality. Because DevOps and cloud native focus on different aspects of the application development process, they complement each other in facilitating agility. DevOps focuses on the principles and practices used in development and operations. A goal of DevOps is to ensure that all team members are cross-functional, so they have a single mindset on improving customer experiences, responding faster to business needs, and ensuring that innovation is balanced with security and operational needs. Cloud native, on the other hand, focuses on the application environment and how to scale and deliver software more efficiently.
The use of a DevOps pipeline to migrate an application toward a microservices architecture achieves the goals of automation, discipline, and repeatability while reducing some of the challenges already identified. As a cloud-native application works its way through the DevOps pipeline, it also moves toward continuous delivery.
Figure 12.17 shows continuous integration and continuous deployment (CI/CD), which is a set of DevOps operating principles that enable development teams to focus on rapid and frequent integrations of new code into the application in development as well as fast and frequent delivery or deployment of new iterations of the application. It allows teams to deliver code changes more frequently and reliably. A DevOps team establishes a CI/CD pipeline, which is a series of steps needed for integration and delivery or deployment that includes the build process through which the application is compiled, built, packaged, and tested. The continuous integration part automates the application compile, build, package, and testing process, enabling it to run independent of physical resources, which allows for a more consistent integration process. This improves team communication and leads to better software quality. The continuous delivery part goes a step further and automates the deployment stage as well. During this phase, the application is deployed to selected infrastructure environments. Packages built during CI are deployed into multiple environments (e.g., development, staging). The application build undergoes integration and performance tests. Finally, the application is deployed into production and made available to end users.
Elastic–Dynamic Scale-Up/Down
Cloud-native applications take advantage of the elasticity of the cloud by scaling microservices. Microservices that require additional resources can be scaled on demand to service an increased capacity. The microservice can also be scaled down when usage decreases. Resources that were allocated during the scale-up can be deallocated as they are no longer needed. A cloud-native application can thus adjust to the increased or decreased resources and scale as needed.
Benefits of Cloud-Native Applications
Cloud-native applications are designed and built to take advantage of the speed and efficiency of the cloud. Cloud-native applications are highly scalable, easy to update, and take advantage of cloud platforms, processes, and services to easily extend their capabilities. Some of the benefits of using cloud-native applications include the following:
- Cost-effectiveness: Orchestration tools can help scale a cloud-native application by automating the allocation of resources to the microservices as needed without having to duplicate the entire application. This eliminates the overprovisioning of hardware and the need for load balancing. Containers can also be used to reduce the complexity of managing the many microservices that make up a cloud-native application as well as maximize the number of microservices that run on a host, saving time, resources, and money.
- Scalability: Each microservice is logically isolated and can scale independently without downtime. Microservices can scale up or down by allocating more or fewer resources to in-demand services in response to a change in user traffic. If one microservice is changed to scale, the others are not affected. Independent scalability also makes it easier to deploy or update any part of the cloud-native application without affecting the entire application.
- Portability: Cloud-native applications are vendor neutral because the containers microservices run in can be deployed anywhere, thereby avoiding vendor lock-in.
- Reliability and resiliency: If a failure occurs in one microservice, there is no effect on adjacent microservices because cloud-native applications use containers. Resiliency is provided at the core of the architecture. As with any software system, failure can also occur in distributed systems and hardware. Transient failures can also occur in networks. The ability of a system to recover from failures and continue to function is called resiliency. The goal of resiliency is to return the application to a fully functioning state following a failure minimizing downtime and data loss. An application is resilient if it (1) has high availability, which is the ability for an application to continue running in a healthy state without significant downtime; and (2) supports disaster recovery, which is the ability of the application to recover from rare but major incidents: nontransient, wide-scale failures, such as service disruption that affects an entire region. Applications can be made resilient by increasing redundancy with multinode clusters, multiregion deployments, and data replication. Other strategies for implementing resiliency include retries to handle transient network failures, adding more nodes to a cluster and load balance across them, throttling high-volume users, and applying circuit breakers to prevent an application from repeatedly trying an operation that is likely to fail.
Testing for resiliency requires testing how the end-to-end workload performs under failure conditions that only occur intermittently—for example, injecting failures by crashing processes, including expired certificates, making dependent services unavailable, and so on. Resiliency tools and frameworks like Chaos Monkey can be used for such chaos testing. For example, Netflix uses Chaos Monkey for resiliency testing to simulate failures and address them. - Ease of management: Cloud-native application updates and added features are automated as they move through a DevOps pipeline using CI/CD. This makes it easier for developers to track the microservices as they are being updated. Development teams can focus on managing specific microservices without worrying about how it will interact with other microservices. This architecture allows teams to be chosen to manage specific microservices based on the skill sets of their members.
- Visibility: Because a microservices architecture isolates services, it makes it easier for teams to learn how the microservices function together and have a better understanding of the cloud-native application as a whole.
Best Practices for Cloud-Native Application Development
Best practices for designing cloud-native applications are based on the DevOps principle of operational excellence to ensure the timely delivery of quality software. A cloud-native architecture has no unique rules, and businesses will approach development differently based on the business problem they are solving and the software they are using. Adopting the DevOps principles to develop cloud-native applications, businesses gain three core advantages, such as higher-quality software released more rapidly, faster responsiveness to customer needs, and improved working environment for development teams.
All cloud-native application designs should consider how the application will be built, how performance is measured, and how teams foster continuous improvement of the application’s performance, compliance through the application life cycle at a faster pace, and higher quality. Here are the five essential best practices for cloud-native application design:
- Automation: A development team should automate as much of the cloud-native application development life cycle as possible. Automation helps reduce human errors and increase team productivity. It also allows for the consistent provisioning of cloud application environments across multiple cloud vendors. With automation, infrastructure as code (IaC) is used as a DevOps practice that uses versioning and a declarative language to automate the provisioning of infrastructure resources such as compute services, networks, and storage.
- Monitoring: Teams should monitor the development environment, as well as how the application is being used. Monitoring ensures the cloud-native application performs without issues. Teams can also bolster the CI/CD pipeline with continuous monitoring of the application, logs, and supporting infrastructure. Continuous monitoring can also be used to identify productivity issues that may slow down the CI/CD pipeline.
- Documentation: Many teams build cloud-native applications with limited to no visibility into what other teams are doing. Teams with specific skills are likely to manage certain aspects of the cloud-native application because microservices are built with different programming languages and frameworks that team members specialize in. It is important to document the specifics of the microservices they manage, track changes, and monitor team contributions to the cloud-native application.
- Incremental releases: Changes made to the cloud-native application or the underlying architecture should be incremental and reversible. With IaC, developers can track changes in a source repository. Updates should be released as often as possible. Incremental releases reduce the possibility of errors and incompatibility issues.
- Design for failure: Processes should be designed for the possibility of failures in a cloud environment. Implementing test frameworks to simulate failures can mitigate risks. They can also be used to learn from failures and to improve the overall functionality of the cloud-native application.
Global Issues in Technology
Local and International Implications of Cloud Applications
While cloud-native applications are used all over the world, specific internationalization (I18N) and localization (L10N) requirements must be observed to facilitate the creation of applications that people can use. Because microservices are part of an application’s back end, they typically return keywords that can be replaced via a I18N/L10N system within the application front end. What is your opinion regarding whether this approach addresses all I18N/L10N requirements for cloud-native applications?
Tools for Cloud-Native Application Development
Several tools are used for the cloud-native application development process. Together, they create a development stack. The following tools are typically found in a cloud-native development stack.
Docker
Docker is an open-source platform that creates, deploys, and manages containers using a common operating system. It isolates resources allowing multiple containers to use the same OS without contention. Docker has become the standard for container technology. An advantage containers offer is portability. Docker containers can be deployed anywhere, on any physical virtual machine or on the cloud. Using Docker helps reduce the size of development and provides smaller footprints of operating systems in containers. Typically measured in megabytes, Docker containers use far fewer resources than virtual machines and start up almost immediately. Docker containers are lightweight, which makes them easily scalable. Figure 12.18 illustrates an overview of the Docker process.
To deploy applications using Docker, the typical first step is to create a Dockerfile. The Dockerfile is a text document that contains instructions for building a Docker image. A Docker image may be based on another image with some additional customization. Docker images are a collection of immutable layers where each instruction in a Dockerfile creates a layer in the image. Once built, Docker images become immutable templates for creating Docker containers, which are running instances of those images containing everything needed for the application to run.
Kubernetes
Kubernetes is an open-source orchestration platform used for automating deployment, scaling, and management of container-based workloads. An example of a Kubernetes platform is shown in Figure 12.19.
The workload refers to an application being run on Kubernetes. The Kubernetes master node includes the control plane, which has several important components, including a service controller, node controller, endpoint controller, replication controller, and scheduler. These components are responsible for features such as load balancing by distributing network requests across containers efficiently; self-healing containers by regularly checking them for good health and where failed containers are replaced or restarted automatically; auto-scaling containers by adding or removing them in accordance with demand; automated deployment to handle setting up and deploying containers to the cloud; storage management to handle the storage needs of all the containers; and handling networking between containers.
The Kubernetes master node comprises several components, including the Kubernetes API server, which plays a crucial role in managing container-based workloads. Additionally, the Kubernetes cluster consists of worker nodes, each containing a kubelet. Working in tandem with the master node, the kubelet handles tasks like scheduling and ensuring the smooth operation of applications deployed within the worker nodes. Kubernetes has evolved into the preferred platform for deploying cloud-native applications. In this ecosystem, the microservices of a cloud-native application interact over the network, deployed and scaled within a Kubernetes cluster.
To deploy a cloud-native application in a Kubernetes environment, microservice containers, pulled from a registry, are deployed in pods. A pod is a small logical unit that runs a container within a worker node in the Kubernetes cluster. A cluster is a set of one or more nodes. Pods are a group of one or more containers with shared storage network resources and a specification for how the containers are run. Containers should only be scheduled together in a single pod if they are tightly coupled and need to share resources. Pods are ephemeral, meaning they are nonpermanent resources. Kubernetes manages the pods rather than the containers directly. The API server on the Kubernetes master node communicates with the worker node to deploy the container in a pod and start it up. Replicas of pods can be increased to scale the containerized microservice within it. If a pod fails, a new one is created. Kubernetes manages these deployments for the length of the deployment until the pod is deleted. In other words, it ensures that all pods and replicas are running.
Service discovery is another important service provided by the Kubernetes platform. As pods are added and replicated, an internal IP address is provided for the pod, making the container accessible. Pods are ephemeral so IP addresses can change as new pods are created. Service registry and service discovery capabilities address this issue by creating Kubernetes services. A Kubernetes service is an abstraction, which defines a logical set of pods and a policy by which to access them in a reliable way.
Think It Through
Are Docker and Kubernetes Too Broad?
Given the fact that many tools are available for containerization and container orchestration, what justifies the broad acceptance of Docker and Kubernetes to handle these respective functions?
Terraform
Terraform is an open-source IaC tool used to build, update, and version cloud and on-premises resources. Some use cases for Terraform include managing Kubernetes clusters and provisioning resources in the cloud, among many others.
GitLab and GitHub CI/CD
GitLab is a cloud-based DevOps platform used to monitor, test, and deploy application code. GitLab includes a cloud-based Git repository as well as several DevOps features such as CI/CD, security, and application development tools. The CI/CD tool can be used to automate testing, deployment, and monitoring applications. GitLab can also be used for security analysis, static analysis, and unit testing. GitHub is a cloud-based developer platform used for software development, collaboration, and security. GitHub also includes a cloud-based Git repository and several DevOps features similar to GitLab.
Red Hat OpenShift
OpenShift is Red Hat’s cloud application platform. It includes several containerization software products, including the OpenShift Container Platform that runs on the Red Hat Linux operating system and Kubernetes. OpenShift is a Platform as a Service (PaaS) that includes the Kubernetes platform, Docker container images, as well as features that are exclusive to the OpenShift platform. Such features include CI/CD pipeline definitions, container automation tools, Kubernetes command-line interface, and security features. OpenShift provides a robust, multilanguage development environment, plus all the necessary software components to support applications. OpenShift is open-source and free-to-download application that enables developers to quickly deploy web, mobile, and IoT applications.
Tanzu
VMWare’s cloud application software Tanzu, formerly known as Cloud Foundry, is a modular, application platform that provides a rich set of developer tools and a pre-paved path to production to build and deploy applications quickly and securely on any compliant public cloud or on-premises Kubernetes cluster. Tanzu provides a supply chain of operational and security outcomes for the development environment via configurations that are designed with operational and security principles so that applications can be pushed into production quickly, run, and scaled safely and securely. Such principles include running code through a testing environment and ensuring the code runs properly, applying security scanning so that the application that goes into production is audited and compliant with security policies, and deploying the application to production environments that may include several cluster environments that can run and scale in production.
Node
Node is an open-source, cross-platform, server-side JavaScript runtime environment that can be used to develop server-side tools and applications in JavaScript. Some examples of real-time applications include chats, news feeds, and other microservices. For example, Node can be used to create virtual servers and define the routes that connect microservices to external APIs such as operating system APIs, including HTTP and file system libraries, compared to browser-specific JavaScript APIs.
Link to Learning
This Cloud Native Trail Map illustrates the use of various open-source tools to develop cloud-native applications.
The Future of Cloud-Native Applications
Cloud-native applications have seen increased use in recent years and are predicted to be the future of software development. The Cloud Native Computing Foundation11 estimated there were at least 6.8 million cloud-native developers in 2021 compared to 6.5 million in 2020. They also estimated there were 5.6 million developers using Kubernetes in 2021, up 67% from a year ago.12
Cloud-native applications solve some of cloud computing’s inherent problems. The cloud-native approach is the new standard for enterprise architecture. It is a way of designing, building, and running applications in the cloud. It has been observed that companies that adopt a cloud-native approach can achieve higher levels of innovation, agility, and scalability. It also offers many benefits such as:
- reducing IT overhead and management costs by providing a streamlined software delivery process and on-demand consumption of resources
- reducing time to market and reducing the risk of deployments by enabling developers to rapidly build, test, and deploy new and updated services
- ability to react faster in the market due to constant availability of resources
- reduction in complexity
- less coupling between the services in an application
Nevertheless, migrating to the cloud to improve operational efficiencies has a range of challenges. We also pointed out earlier some of the challenges faced in microservices architectures. Some of the challenges that were learned earlier include to use microservices requires changing the allocation of responsibility between components, and determining the components’ service boundaries could be difficult, debugging, logging, and monitoring microservices also become challenging, to name a few.
Technology in Everyday Life
Everyday Life and Microservices
There are myriads of web apps that people use every day that are based on microservices. For example, weather apps typically leverage web services that invoke microservices. More complex applications include e-commerce websites, as illustrated earlier. Can you provide additional illustrative scenarios that demonstrate how the use of microservices help people in everyday life? Your scenarios should not be limited to describing how microservices are used, but rather should describe situations where these architectures are applied in real-life contexts.
Footnotes
- 1For information on the SOAP Messaging Protocol, see https://www.w3.org/TR/2007/REC-soap12-part1-20070427/
- 2For information on ActiveMQ, see https://activemq.apache.org/
- 3For information on Apache Thrift, see https://thrift.apache.org/
- 4https://aws.amazon.com/blogs/mobile/backends-for-frontends-pattern/
- 5For information about Helios, see https://snyk.io/blog/welcoming-helios-to-snyk/
- 6For information about Rookout, see https://www.rookout.com/
- 7For information about Lightrun, see https://lightrun.com/
- 8Diagram is modernized by writer and based off https://devblogs.microsoft.com/premier-developer/wp-content/uploads/sites/31/2020/03/cloud-native-design.png
- 9https://about.netflix.com/en/news/completing-the-netflix-cloud-migration
- 10https://www.cncf.io/case-studies/netflix/
- 11https://www.cncf.io/
- 12https://www.cncf.io/blog/2021/12/20/new-slashdata-report-5-6-million-developers-use-kubernetes-an-increase-of-67-over-one-year/
{kind=link}